Question 136
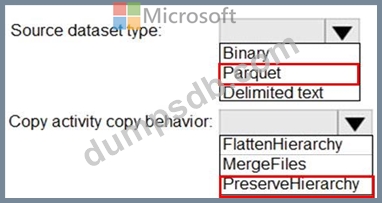
You have two Azure Storage accounts named Storage1 and Storage2. Each account holds one container and has the hierarchical namespace enabled. The system has files that contain data stored in the Apache Parquet format.
You need to copy folders and files from Storage1 to Storage2 by using a Data Factory copy activity. The solution must meet the following requirements:
No transformations must be performed.
The original folder structure must be retained.
Minimize time required to perform the copy activity.
How should you configure the copy activity? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Question 137
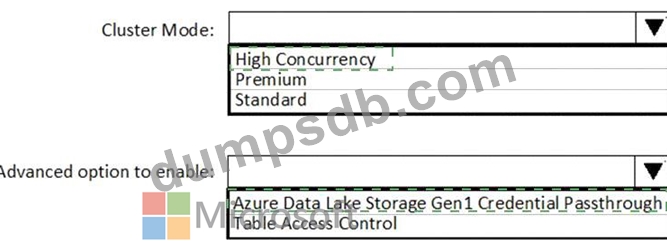
You need to implement an Azure Databricks cluster that automatically connects to Azure Data Lake Storage Gen2 by using Azure Active Directory (Azure AD) integration.
How should you configure the new cluster? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.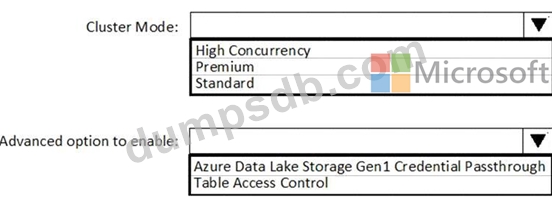

Question 138
You have a table in an Azure Synapse Analytics dedicated SQL pool. The table was created by using the following Transact-SQL statement.
You need to alter the table to meet the following requirements:
* Ensure that users can identify the current manager of employees.
* Support creating an employee reporting hierarchy for your entire company.
* Provide fast lookup of the managers' attributes such as name and job title.
Which column should you add to the table?
Question 139
You have an Azure Synapse Analytics serverless SQL pool named Pool1 and an Azure Data Lake Storage Gen2 account named storage1. The AllowedBlobpublicAccess porperty is disabled for storage1.
You need to create an external data source that can be used by Azure Active Directory (Azure AD) users to access storage1 from Pool1.
What should you create first?
Question 140
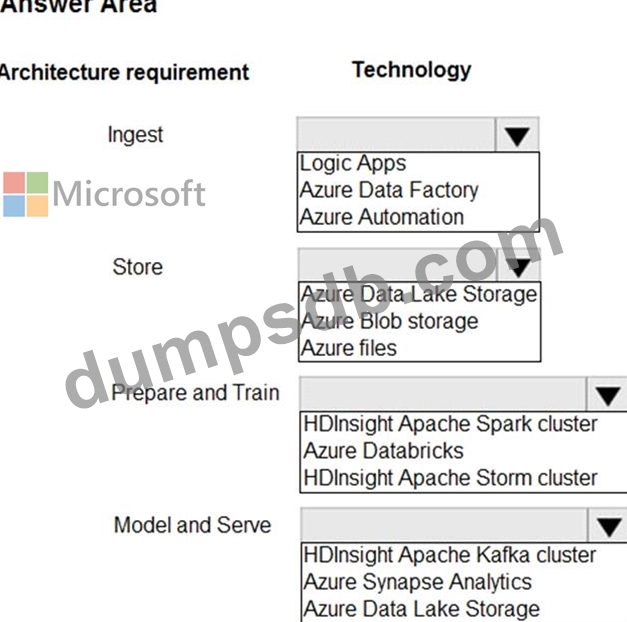
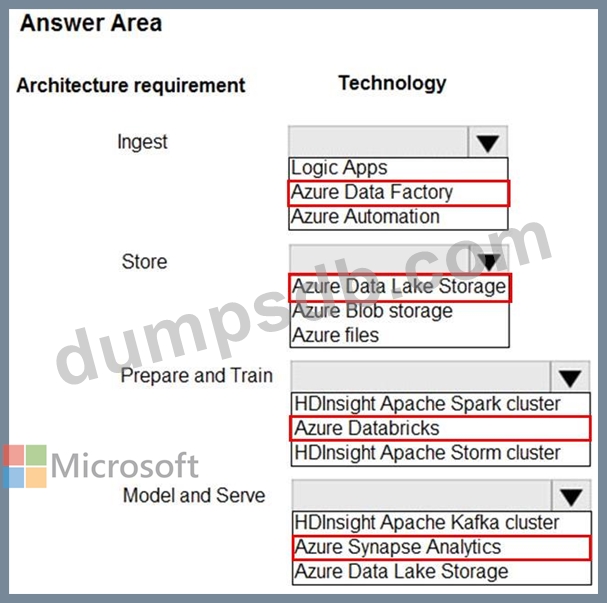
A company plans to use Platform-as-a-Service (PaaS) to create the new data pipeline process. The process must meet the following requirements:
Ingest:
Access multiple data sources.
Provide the ability to orchestrate workflow.
Provide the capability to run SQL Server Integration Services packages.
Store:
Optimize storage for big data workloads.
Provide encryption of data at rest.
Operate with no size limits.
Prepare and Train:
Provide a fully-managed and interactive workspace for exploration and visualization.
Provide the ability to program in R, SQL, Python, Scala, and Java.
Provide seamless user authentication with Azure Active Directory.
Model & Serve:
Implement native columnar storage.
Support for the SQL language
Provide support for structured streaming.
You need to build the data integration pipeline.
Which technologies should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.