You have a data warehouse in Azure Synapse Analytics. You need to ensure that the data in the data warehouse is encrypted at rest. What should you enable?
Correct Answer: A
Transparent data encryption (TDE) helps protect Azure SQL Database, Azure SQL Managed Instance, and Azure Synapse Analytics against the threat of malicious offline activity by encrypting data at rest. Reference: https://docs.microsoft.com/en-us/azure/azure-sql/database/transparent-data-encryption-tde-overview
Question 57
You have an Azure SQL database that contains a table named Employees. Employees contains a column named Salary. You need to encrypt the Salary column. The solution must prevent database administrators from reading the data in the Salary column and must provide the most secure encryption. Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Correct Answer:
Explanation: Step 1: Create a column master key Create a column master key metadata entry before you create a column encryption key metadata entry in the database and before any column in the database can be encrypted using Always Encrypted. Step 2: Create a column encryption key. Step 3: Encrypt the Salary column by using the randomized encryption type. Randomized encryption uses a method that encrypts data in a less predictable manner. Randomized encryption is more secure, but prevents searching, grouping, indexing, and joining on encrypted columns. Note: A column encryption key metadata object contains one or two encrypted values of a column encryption key that is used to encrypt data in a column. Each value is encrypted using a column master key. Incorrect Answers: Deterministic encryption. Deterministic encryption always generates the same encrypted value for any given plain text value. Using deterministic encryption allows point lookups, equality joins, grouping and indexing on encrypted columns. However, it may also allow unauthorized users to guess information about encrypted values by examining patterns in the encrypted column, especially if there's a small set of possible encrypted values, such as True/False, or North/South/East/West region. Reference: https://docs.microsoft.com/en-us/sql/relational-databases/security/encryption/always-encrypted-database-engine
Question 58
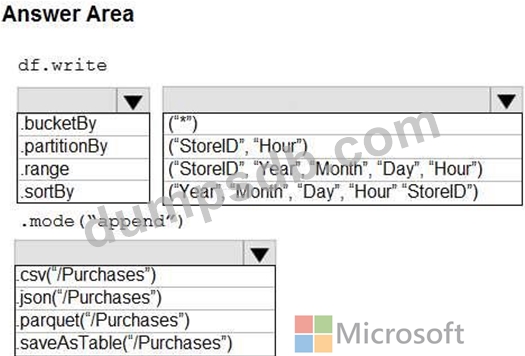
HOTSPOT You plan to develop a dataset named Purchases by using Azure Databricks. Purchases will contain the following columns: * ProductID * ItemPrice * LineTotal * Quantity * StoreID * Minute * Month * Hour * Year * Day You need to store the data to support hourly incremental load pipelines that will vary for each StoreID. The solution must minimize storage costs. How should you complete the code? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
You have an Azure SQL database. Users report that the executions of a stored procedure are slower than usual. You suspect that a regressed query is causing the performance issue. You need to view the query execution plan to verify whether a regressed query is causing the issue. The solution must minimize effort. What should you use?
Correct Answer: C
Use the Query Store Page in SQL Server Management Studio. Query performance regressions caused by execution plan changes can be non-trivial and time consuming to resolve. Since the Query Store retains multiple execution plans per query, it can enforce policies to direct the Query Processor to use a specific execution plan for a query. This is referred to as plan forcing. Plan forcing in Query Store is provided by using a mechanism similar to the USE PLAN query hint, but it does not require any change in user applications. Plan forcing can resolve a query performance regression caused by a plan change in a very short period of time. Reference: https://docs.microsoft.com/en-us/sql/relational-databases/performance/monitoring-performance-by-using-the-query-store
Question 60
You have an Azure Data Factory pipeline that is triggered hourly. The pipeline has had 100% success for the past seven days. The pipeline execution fails, and two retries that occur 15 minutes apart also fail. The third failure returns the following error. What is a possible cause of the error?
Correct Answer: B
Section: [none] Explanation: A file is missing. Testlet 1 Case study This is a case study. Case studies are not timed separately. You can use as much exam time as you would like to complete each case. However, there may be additional case studies and sections on this exam. You must manage your time to ensure that you are able to complete all questions included on this exam in the time provided. To answer the questions included in a case study, you will need to reference information that is provided in the case study. Case studies might contain exhibits and other resources that provide more information about the scenario that is described in the case study. Each question is independent of the other questions in this case study. At the end of this case study, a review screen will appear. This screen allows you to review your answers and to make changes before you move to the next section of the exam. After you begin a new section, you cannot return to this section. To start the case study To display the first question in this case study, click the Next button. Use the buttons in the left pane to explore the content of the case study before you answer the questions. Clicking these buttons displays information such as business requirements, existing environment, and problem statements. If the case study has an All Information tab, note that the information displayed is identical to the information displayed on the subsequent tabs. When you are ready to answer a question, click the Question button to return to the question. Overview Litware, Inc. is a renewable energy company that has a main office in Boston. The main office hosts a sales department and the primary datacenter for the company. Physical Locations Litware has a manufacturing office and a research office is separate locations near Boston. Each office has its own datacenter and internet connection. Existing Environment Network Environment The manufacturing and research datacenters connect to the primary datacenter by using a VPN. The primary datacenter has an ExpressRoute connection that uses both Microsoft peering and private peering. The private peering connects to an Azure virtual network named HubVNet. Identity Environment Litware has a hybrid Azure Active Directory (Azure AD) deployment that uses a domain named litwareinc.com. All Azure subscriptions are associated to the litwareinc.com Azure AD tenant. Database Environment The sales department has the following database workload: * An on-premises named SERVER1 hosts an instance of Microsoft SQL Server 2012 and two 1-TB databases. * A logical server named SalesSrv01A contains a geo-replicated Azure SQL database named SalesSQLDb1, SalesSQLDb1 is in an elastic pool named SalesSQLDb1Pool. SalesSQLDb1 uses database firewall rules and contained database users. * An application named SalesSQLDb1App1 uses SalesSQLDb1. The manufacturing office contains two on-premises SQL Server 2016 servers named SERVER2 and SERVER3. The servers are nodes in the same Always On availability group. The availability group contains a database named ManufacturingSQLDb1. Database administrators have two Azure virtual machines in HubVnet named VM1 and VM2 that run Windows Server 2019 and are used to manage all the Azure databases. Licensing Agreement Litware is a Microsoft Volume Licensing customer that has License Mobility through Software Assurance. Current Problems Requirements SalesSQLDb1 experiences performance issues that are likely due to out-of-date statistics and frequent blocking queries. Planned Changes Litware plans to implement the following changes: * Implement 30 new databases in Azure, which will be used by time-sensitive manufacturing apps that have varying usage patterns. Each database will be approximately 20 GB. * Create a new Azure SQL database named ResearchDB1 on a logical server named ResearchSrv01. ResearchDB1 will contain Personally Identifiable Information (PII) data. * Develop an app named ResearchApp1 that will be used by the research department to populate and access ResearchDB1. * Migrate ManufacturingSQLDb1 to the Azure virtual machine platform. * Migrate the SERVER1 databases to the Azure SQL Database platform. Technical Requirements Litware identifies the following technical requirements: * Maintenance tasks must be automated. * The 30 new databases must scale automatically. * The use of an on-premises infrastructure must be minimized. * Azure Hybrid Use Benefits must be leveraged for Azure SQL Database deployments. * All SQL Server and Azure SQL Database metrics related to CPU and storage usage and limits must be analyzed by using Azure built-in functionality. Security and Compliance Requirements Litware identifies the following security and compliance requirements: * Store encryption keys in Azure Key Vault. * Retain backups of the PII data for two months. * Encrypt the PII data at rest, in transit, and in use. * Use the principle of least privilege whenever possible. * Authenticate database users by using Active Directory credentials. * Protect Azure SQL Database instances by using database-level firewall rules. * Ensure that all databases hosted in Azure are accessible from VM1 and VM2 without relying on public endpoints. Business Requirements Litware identifies the following business requirements: * Meet an SLA of 99.99% availability for all Azure deployments. * Minimize downtime during the migration of the SERVER1 databases. * Use the Azure Hybrid Use Benefits when migrating workloads to Azure. * Once all requirements are met, minimize costs whenever possible.