Which of the following string functions are predicate functions? Note: There are 2 correct answers to this question.
Correct Answer: B,D
String functions are expressions that can be used to manipulate character-like data in ABAP. String functions can be either predicate functions or non-predicate functions. Predicate functions are string functions that return a truth value (true or false) for a condition of the argument text. Non-predicate functions are string functions that return a character-like result for an operation on the argument text1. The following string functions are predicate functions: * B. contains_any_of(): This function returns true if the argument text contains at least one of the characters specified in the character set. For example, the following expression returns true, because the text 'ABAP' contains at least one of the characters 'A', 'B', or 'C': contains_any_of( val = 'ABAP' set = 'ABC' ). * D. matches(): This function returns true if the argument text matches the pattern specified in the regular expression. For example, the following expression returns true, because the text 'ABAP' matches the pattern that consists of four uppercase letters: matches( val = 'ABAP' regex = '[A-Z]{4}' ). The following string functions are not predicate functions, because they return a character-like result, not a truth value: * A. find_any_not_of(): This function returns the position of the first character in the argument text that is not contained in the character set. If no such character is found, the function returns 0. For example, the following expression returns 3, because the third character of the text 'ABAP' is not contained in the character set 'ABC': find_any_not_of( val = 'ABAP' set = 'ABC' ). * C. count_any_of(): This function returns the number of characters in the argument text that are * contained in the character set. For example, the following expression returns 2, because there are two characters in the text 'ABAP' that are contained in the character set 'ABC': count_any_of( val = 'ABAP' set = 'ABC' ). References: 1: String Functions - ABAP Keyword Documentation
Question 2
In what order are objects created to generate a RESTful Application Programming application?
Correct Answer: C
The order in which objects are created to generate a RESTful Application Programming application is A, D, C, B. This means that the following steps are followed: * First, a database table is created to store the data for the application. A database table is a CDS DDIC-based view that defines a join or union of database tables. A database table has an SQL view attached and can be accessed by Open SQL or native SQL. * Second, a data model view is created to define a data model based on the database table or other CDS view entities. A data model view is a CDS view entity that can have associations, aggregations, filters, parameters, and annotations. A data model view can also define the behavior definition and implementation for the business object. * Third, a service definition is created to define the service interface for the application. A service definition is a CDS view entity that defines a projection on a data model view or another service definition. A service definition can also define service metadata, such as service name, version, description, and annotations. * Fourth, a service binding is created to define the service binding for the application. A service binding is a CDS view entity that defines a projection on a service definition. A service binding can also define the service protocol, such as OData V2, OData V4, or REST, and the service URL. References: CDS Data Model Views - ABAP Keyword Documentation, CDS Service Definitions - ABAP Keyword Documentation, CDS Service Bindings - ABAP Keyword Documentation, CDS Projection Views - ABAP Keyword Documentation
Question 3
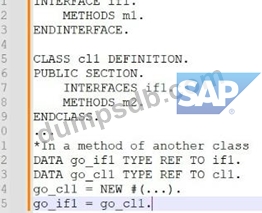
Exhibit: What are valid statements? Note: There are 3 correct answers to this question.
Correct Answer: A,B,E
The following are the explanations for each statement: A: This statement is valid. go_ifl may call method ml with go_ifl->ml(). This is because go_ifl is a data object of type REF TO ifl, which is a reference to the interface ifl. The interface ifl defines a method ml, which can be called using the reference variable go_ifl. The class cll implements the interface ifl, which means that it provides an implementation of the method ml. The data object go_ifl is assigned to a new instance of the class cll using the NEW operator and the inline declaration operator @DATA. Therefore, when go_ifl->ml() is called, the implementation of the method ml in the class cll is executed123 B: This statement is valid. Instead of go_cll = NEW #(...) you could use go_ifl = NEW cll(...). This is because go_ifl is a data object of type REF TO ifl, which is a reference to the interface ifl. The class cll implements the interface ifl, which means that it is compatible with the interface ifl. Therefore, go_ifl can be assigned to a new instance of the class cll using the NEW operator and the class name cll. The inline declaration operator @DATA is optional in this case, as go_ifl is already declared. The parentheses after the class name cll can be used to pass parameters to the constructor of the class cll, if any123 E: This statement is valid. go_ifl may call method m2 with go_ifl->m2(...). This is because go_ifl is a data object of type REF TO ifl, which is a reference to the interface ifl. The class cll implements the interface ifl, which means that it inherits all the components of the interface ifl. The class cll also defines a method m2, which is a public method of the class cll. Therefore, go_ifl can call the method m2 using the reference variable go_ifl. The method m2 is not defined in the interface ifl, but it is accessible through the interface ifl, as the interface ifl is implemented by the class cll. The parentheses after the method name m2 can be used to pass parameters to the method m2, if any123 The other statements are not valid, as they have syntax errors or logical errors. These statements are: C: This statement is not valid. go_cll may call method ml with go_cll->ifl~ml(). This is because go_cll is a data object of type REF TO cll, which is a reference to the class cll. The class cll implements the interface ifl, which means that it inherits all the components of the interface ifl. The interface ifl defines a method ml, which can be called using the reference variable go_cll. However, the syntax for calling an interface method using a class reference is go_cll->ml(), not go_cll->ifl~ml(). The interface component selector ~ is only used when calling an interface method using an interface reference, such as go_ifl->ifl~ml(). Using the interface component selector ~ with a class reference will cause a syntax error123 D: This statement is not valid. Instead of go_cll = NEW #() you could use go_ifl = NEW #(...). This is because go_ifl is a data object of type REF TO ifl, which is a reference to the interface ifl. The interface ifl cannot be instantiated, as it does not have an implementation. Therefore, go_ifl cannot be assigned to a new instance of the interface ifl using the NEW operator and the inline declaration operator @DATA. This will cause a syntax error or a runtime error. To instantiate an interface, you need to use a class that implements the interface, such as the class cll123
Question 4
In what order are objects created to generate a RESTful Application Programming application?
Correct Answer: C
Explanation The order in which objects are created to generate a RESTful Application Programming application is A, D, C, B. This means that the following steps are followed: First, a database table is created to store the data for the application. A database table is a CDS DDIC-based view that defines a join or union of database tables. A database table has an SQL view attached and can be accessed by Open SQL or native SQL. Second, a data model view is created to define a data model based on the database table or other CDS view entities. A data model view is a CDS view entity that can have associations, aggregations, filters, parameters, and annotations. A data model view can also define the behavior definition and implementation for the business object. Third, a service definition is created to define the service interface for the application. A service definition is a CDS view entity that defines a projection on a data model view or another service definition. A service definition can also define service metadata, such as service name, version, description, and annotations. Fourth, a service binding is created to define the service binding for the application. A service binding is a CDS view entity that defines a projection on a service definition. A service binding can also define the service protocol, such as OData V2, OData V4, or REST, and the service URL. References: CDS Data Model Views - ABAP Keyword Documentation, CDS Service Definitions - ABAP Keyword Documentation, CDS Service Bindings - ABAP Keyword Documentation, CDS Projection Views - ABAP Keyword Documentation
Question 5
Given the following Core Data Service View Entity Data Definition: 1 @AccessControl.authorizationCheck: #NOT_REQUIRED 2 DEFINE VIEW ENTITY demo_flight_info_join 3 AS SELECT 4 FROM scarr AS a 5 LEFT OUTER JOIN scounter AS c 6 LEFT OUTER JOIN sairport AS p 7 ON p.id = c.airport 8 ON a.carrid = c.carrid 9 { 10 a.carridAS carrier_id, 11 p.idAS airport_id, 12 c.countnumAS counter_number 13 } In what order will the join statements be executed?
Correct Answer: A
The order in which the join statements will be executed is: scarr will be joined with scounter first and the result will be joined with sairport. This is because the join statements are nested from left to right, meaning that the leftmost data source is joined with the next data source, and the result is joined with the next data source, and so on. The join condition for each pair of data sources is specified by the ON clause that follows the data source name. The join type for each pair of data sources is specified by the join operator that precedes the data source name. In this case, the join operator is LEFT OUTER JOIN, which means that all the rows from the left data source are included in the result, and only the matching rows from the right data source are included. If there is no matching row from the right data source, the corresponding fields are filled with initial values1. Therefore, the join statements will be executed as follows: * First, scarr AS a will be joined with scounter AS c using the join condition a.carrid = c.carrid. This means that all the rows from scarr will be included in the result, and only the rows from scounter that have the same value for the carrid field will be included. If there is no matching row from scounter, the countnum field will be filled with an initial value. * Second, the result of the first join will be joined with sairport AS p using the join condition p.id = c.airport. This means that all the rows from the first join will be included in the result, and only the rows from sairport that have the same value for the id field as the airport field from the first join will be included. If there is no matching row from sairport, the id field will be filled with an initial value. References: 1: Join - ABAP Keyword Documentation